May 11, 2026
Radmila
Cloud Cost Optimization & FinOps
Listen
Our Azure Bill Was Out of Control - Here's How We Cut it by 62%
At one point, our Azure bill stopped making sense.
Every month, the number kept climbing, but our traffic growth didn’t match the increase. We expected some scaling costs, that’s normal in cloud environments. But this felt different. The infrastructure was stable, deployments were smooth, and nothing appeared broken. Yet somehow, the monthly spend kept getting worse.
At first, we ignored it.
Like many teams, we assumed the rising costs were simply part of our growth. More services, more environments, more users. But after another painful invoice landed in our inbox, we finally decided to investigate where the money was actually going.
What we found surprised us.
The problem wasn’t a single expensive service, or a major architectural mistake. It was dozens of small decisions that had quietly accumulated over time. Logging configurations nobody revisited. Oversized Kubernetes clusters left “temporarily” scaled up. Premium storage tiers that became permanent defaults. Old environments that nobody shut down.
Individually, none of these looked alarming. Together, they were burning money every single day.
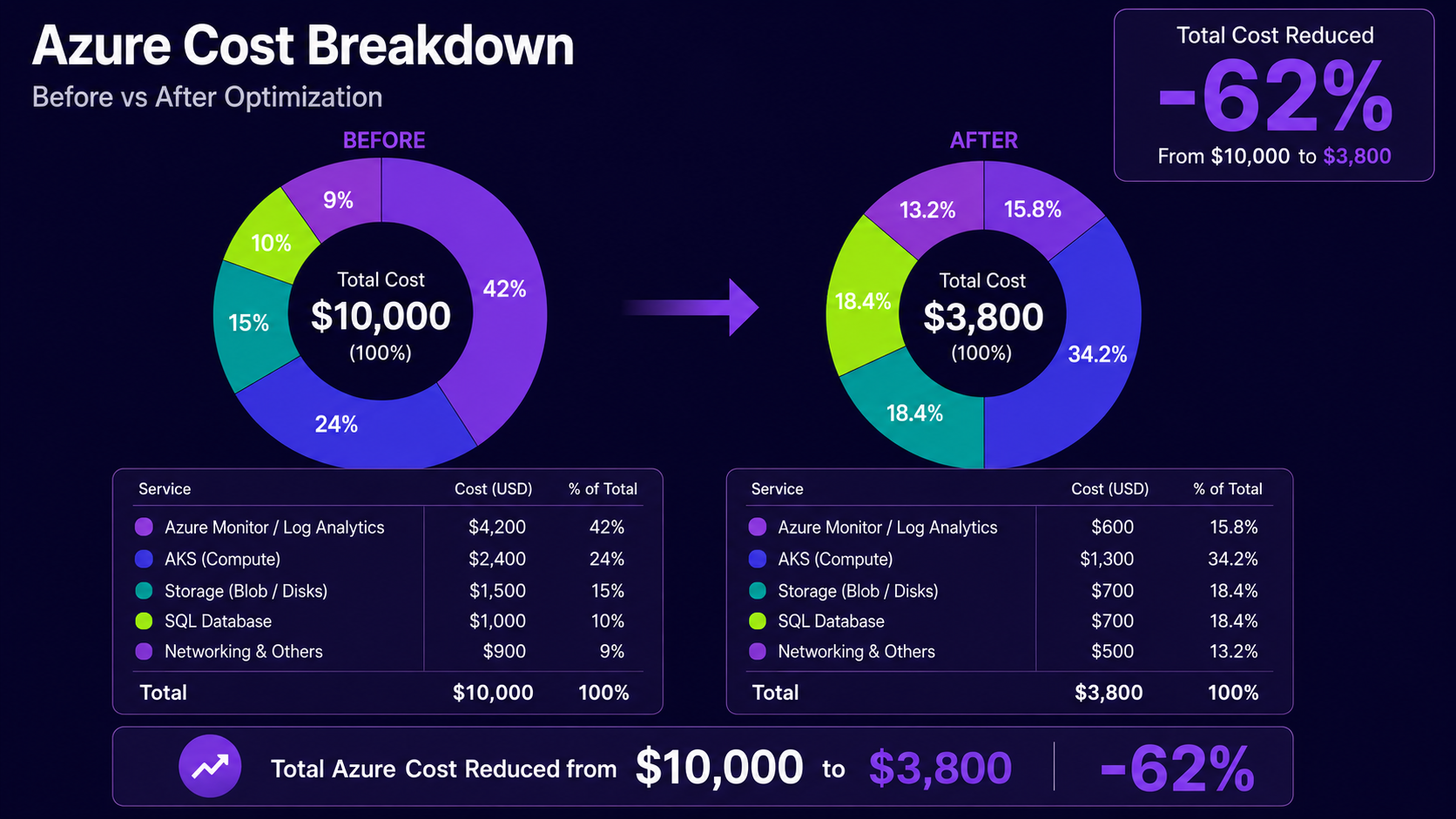
Over the next few weeks, we audited the entire Azure environment and reduced our cloud costs by 62% without affecting performance, uptime, or developer workflows.
Here's exactly what we changed.
Our infrastructure was a fairly standard Azure setup:
From an engineering perspective, everything looked healthy. Applications performed well, alerts were quiet, and deployments were reliable. That was the dangerous part. Because nothing felt urgent, nobody questioned the infrastructure decisions we made months earlier.
Until we opened Azure Cost Analysis.
We expected compute to be the biggest expense. It wasn’t.
Azure Monitor and Log Analytics were consuming a massive portion of the monthly bill. The more we investigated, the worse it got.
We had diagnostic logging enabled almost everywhere:
At some point, the environment turned into a “log everything” strategy. The logic made sense at the time: more logs meant better visibility. But the reality was that more logs also meant massive ingestion costs.
Some Kubernetes workloads were generating huge amounts of container logs that nobody ever reviewed. We also found duplicate diagnostic settings and long retention policies enabled by default. The platform wasn’t failing. It was just noisy.
So we started cleaning it up. We reduced retention periods, filtered unnecessary Kubernetes logs, removed unused diagnostics, and enabled adaptive sampling in Application Insights.
Almost immediately, monitoring costs dropped significantly. Ironically, troubleshooting became easier too because dashboards contained less noise and more useful signals.
Next, we looked at Kubernetes, and honestly, that was painful.
Months earlier, during a high-traffic, we scaled several node pools aggressively to avoid performance issues. The intention was good: better to overpoison than risk downtime. The problem was that nobody revisited those decisions afterward.
When we reviewed utilization metrics, average CPU usage across some node pools was below 20%. Memory usage wasn’t much better. Several workloads have inflated resource requests copied from older deployments and never adjusted again.
In practice, we were paying for a large amount of capacity we barely used.
We started optimizing by right-sizing resource requests, enabling Cluster Autoscaler, separating workloads into dedicated node pools, and moving non-critical services to smaller VM SKUs.
We expected some performance trade-offs. They never came.
The applications performed exactly the same, but the compute bill looked completely different.
The same pattern appeared in storage.
Many Blob Storage accounts were still using the Hot tier even though older files were rarely accessed. Several managed disks were running on Premium SSDs despite minimal throughput requirements. Some SQL databases were also provisioned far above their actual usage.
Again, none of this happened because of bad engineering. Most of these choices were originally made for safety, speed, or simplicity. But in cloud environments, temporary decisions often become permanent infrastructure.
We introduced lifecycle policies that automatically moved older data into cheaper storage tiers. We downgraded unnecessary Premium SSDs and resized databases based on real performance metrics instead of assumptions.
Nobody noticed the difference operationally. But the invoice definitely did.
The final cleanup was probably the most annoying part of the entire process.
We found old test environments, unused public IPs, unattached disks, stale snapshots, abandoned App Service Plans, and resources nobody could confidently explain.
None of them were individually expensive. But cloud waste rarely comes from one catastrophic mistake. It comes from infrastructure that quietly survives long after it stops being useful.
After that, we introduced stricter governance:
Because if nobody owns a resource, it usually stays alive forever.
The biggest lesson from this project was surprisingly simple: cloud costs grow silently.
Most of the expensive decisions weren’t dramatic failures. They were reasonable choices nobody revisited later. For example keeping logs “just in case,” scaling clusters conservatively, defaulting to premium tiers, or leaving environments running longer than planned.
Everything technically worked. But “working” and “efficient” are not the same thing.
After several weeks of auditing and optimization:
More importantly, cost optimization stopped being a one-time cleanup exercise and became part of how we approach infrastructure engineering.
Because the real danger with cloud platforms is not how expensive they are initially. It’s how easy it is for unnecessary costs to become normal over time.
Designing and developing digital experiences that move businesses forward.
Contact
hello@hoppsolutions.com
+49 155 1027 5723
+389 77 540 743
Office
Bul. Turisticka 21
6000 Ohrid, North Macedonia
Made with love by Hopp Solutions | 2026


